探秘X86架构CPU流水线


英文原文:A Journey Through the CPU Pipeline
作为程序员,CPU 在我们的工作中扮演了核心角色,因此了解处理器内部的工作方式对程序员来说不无裨益。
CPU 是如何工作的呢?一条指令执行需要多长时间?当我们讨论某个新款处理器拥有 12 级流水线还是 18 级流水线,甚至是更深的 31 级流水线时,这到些都意味着什么呢?
应用程序通常会将 CPU 看作是黑盒子。程序中的指令按照顺序依次进入 CPU,执行完之后再按顺序依次从 CPU 中出来,而内部到底发生了什么,我们通常并不了解。
对我们程序员来说,尤其是对做程序性能调优工作的程序员来说,学习 CPU 内部的细节非常必要。否则,如果你不知道 CPU 的内部结构,那如何才能针对 CPU 做性能优化?
本文所关注的就是专门针对 X86 处理器流水线的工作原理。
你需要掌握的预备知识
首先,阅读本文你需要了解编程,最好了解一点汇编语言。如果你还不知道指令指针(instruction pointer)是什么,那么本文对你来说可能有些难。你需要知道什么是寄存器,指令和缓存,如果不明白它们是什么,你需要尽快查找资料了解一下。
第二,CPU 的工作原理是一个非常庞大和复杂的话题,本文仅仅是匆匆一瞥,很难以用一篇文章详尽叙述。如果我有什么疏漏,请通过评论告诉我。
第三,我仅仅关注英特尔处理器及其 X86 架构。当然除了 X86,还有很多其他架构的处理器。虽然 AMD 公司引入了很多新特性到 X86 架构,但是 X86 架构是 Intel 公司发明,并且创造了 X86 指令集,其中绝大多数特性是由 Intel 引入的。所以为了保持叙述的简单和一致性,我仅关注 Intel 的处理器。
最后,当你读到这篇文章时,它已经是“过时”的了。更新款的处理器已经设计出来,其中一些会在未来几个月之内发布。我很高兴技术能如此快速的发展,我希望有一天所有这些技术都会过时,创造出拥有更惊人计算能力的 CPU.
处理器流水线基础
从一个非常广的角度来说,X86 处理器架构在近 35 年来并没有变化太多。虽然 X86 架构被附加了很多新功能,但是最初的设计(包括几乎所有最初的指令集)仍然基本上是完整保留的,即使在最新的处理器上仍然被支持。
最初的 8086 处理器支持 14 个寄存器,这些寄存器在如今最新的处理器中仍然存在。这 14 个寄存器中,有 4 个是通用寄存器:AX,BX,CX 和 DX;有 4 个是段寄存器,段寄存器用来辅助指针的实现:代码段(CS),数据段(DS),扩展段(ES)和堆栈段(SS);有 4 个是索引寄存器,用来指向内存地址:源引用(SI),目的引用(DI),基指针(BP),栈指针(SP);有 1 个寄存器包含状态位;最后是最重要的寄存器:指令指针(IP)。
指令指针寄存器是一个拥有特殊功能的指针。指令指针的功能是指向将要运行的下一条指令。
所有的 X86 处理器都按照相同的模式运行。首先,根据指令指针指向的地址取得下一条即将运行的指令并解析该指令(译码)。在译码完成后,会有一个指令的执行阶段。有些指令用来从内存读取数据或者向内存写数据,有些指令用来执行计算或者比较等工作。当指令执行完成后,这条指令会通过退出(retire)阶段并将指令指针修改为下一条指令。
译码,执行和退出三级流水线组成了 X86 处理器指令执行的基本模式。从最初的 8086 处理器到最新的酷睿 i7 处理器都基本遵循了这样的过程。虽然更新的处理器增加了更多的流水级,但基本的模式没有改变。
35 年来发生了什么改变
相较于现今的标准,最初的处理器设计显得太过简单。最初的 8086 处理器的执行过程可以简述为从当前指令指针取得指令,通过译码,执行最后退出,然后继续从指令指针指向的下一条指令处取得指令。
新的处理器增加了新的功能,有些增加了新的指令,有些增加了新的寄存器。我将主要关注和本文主题有关系的改变,这些改变影响了 CPU 指令执行的流程。其他的一些变化比如虚拟内存或者并行处理虽然都很有意义而且有趣,但是并不在本文主题的范围内。
指令缓存在 1982 年被加入到处理器中。通过指令缓存,处理器可以一次性从内存读取更多指令并放在指令缓存中,而不用每条指令都从内存中取。指令缓存仅有几个字节大小,只能容纳数条指令,但是因为消除了之后每次取指往返内存和处理器的时间,极大的提高的效率
1985 年的 386 处理器引入了数据缓存,而且扩展了指令缓存的设计。数据访存请求通过一次性读取更多的数据放在数据缓存中,从而提升了性能。而且,数据缓存和指令缓存都从几个字节扩大到几千字节。
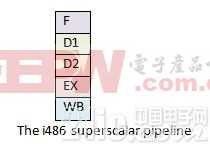
19巴久年推出的 i486 处理器引入了五级流水线。这时,在 CPU 中不再仅运行一条指令,每一级流水线在同一时刻都运行着不同的指令。这个设计使得 I486 比同频率的 386 处理器性能提升了不止一倍。五级流水线中的取指阶段将指令从指令缓存中取出(i486 中的指令缓存为 8KB);第二级为译码阶段,将取出的指令翻译为具体的功能操作;第三级为转址阶段,用来将内存地址和偏移进行转换;第四级为执行阶段,指令在该阶段真正执行运算;第五级为退出阶段,运算的结果被写回寄存器或者内存。由于处理器同时运行了多条指令,大大提升了程序运行的性能。
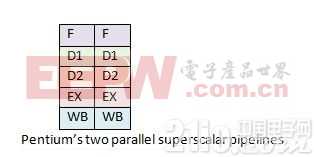
1993 年 Intel 推出了奔腾(Pentium)处理器。由于诉讼问题,Intel 无法继续沿用原来的数字编号。因此,用奔腾替代了 586 作为新款处理器的代号。奔腾处理器相对 i486 处理器对流水线做出了更多修改。奔腾处理器架构增加了第二条独立的超标量流水线。主流水线工作方式类似于 i486,第二条流水线则并行的运行一些较简单的指令,比如说定点算术,而且该流水线能更快的进行该运算。
1995 年 Intel 推出了奔腾 Pro (Pentium Pro)处理器。和之前的处理器相比,奔腾 Pro 采用了完全不同的设计。该处理器采用了诸多新特性以提高性能,包括乱序(Out-of-Order, OOO)执行的部件以及猜测执行。流水线扩展到了 12 级,而且引入了“超标量流水线”的概念,使得许多指令可以被同时处理。我们稍后将详尽的介绍乱序执行的部件。
在 1995-2002 年之间,乱序执行部件经过了数次重大改进。处理器中加入了更多的寄存器;单指令多数据(Single Instruction Multiple Data, or SIMD)的引入使得一条指令可以进行多组数据运算;现有的缓存变得更大而且引入了新的缓存;有些流水级被拆分成更多流水级,有些流水级被合并,使得更加适合实际的应用。这些改变对整体性能的提升有重要作用,但它们都没有从根本影响数据在处理器中的流动方式。
2002 年发布的奔腾 4 处理器引入了超线程技术。乱序执行部件的设计使得指令被执行的速度比处理器能够提供指令的速度更快。因此对于大部分应用,CPU 的乱序执行部件在大部分时间处于空闲状态,甚至在高负载的情况下也不能充分利用。为了让指令流能充分的流入乱序执行部件,Intel 加入了第二套前端部件(译注:在处理器结构中,前端是指取指,译码,寄存器重命名等模块,经过前端部件的处理后,指令等待发射进入乱序执行部件)。虽然实际上只有一个乱序执行部件,但对于操作系统来说,它能看到两个处理器。前端部件包含两组同样功能的 X86 寄存器,两个指令译码器根据两个指令指针指向的地址分别处理。所有的指令被一个共享的乱序执行部件执行,但对应用程序来说并不知情。当乱序执行部件执行完成,像之前一样退出流水线后,最终结果返回虚拟的两个处理器。
2006 年 Intel 发布了酷睿(Core)微架构。为了品牌效应,它被称做酷睿2(二总比一好)。令人惊讶的是,处理器频率不升反降,而且超线程也被去掉了。通过降低时钟频率,每一级流水线可以做更多工作。乱序执行部件也被扩展的更宽。各种不同的缓存和队列都相应做的更大。而且处理器被重新设计,以适应双核和四核的共享缓存结构。
2008 年,Intel 开始用酷睿 i3, i5, i7 的方式来命名新的处理器。新处理器重新引入了超线程。这三个系列的处理器主要区别在于内部缓存大小不同。
未来的处理器:Intel 的下一代微结构被称为 Haswell.Haswell 据称将于 2013 年发布。目前已知的文档说明它将拥有 14 级流水级的乱序执行部件,所以它仍然遵循从奔腾 Pro 以来的基本设计思路。
那么,流水线到底是什么?乱序执行部件是什么?他们如何提升了处理器的性能呢?
CPU 指令流水线
根据之前描述的基础,指令进入流水线,通过流水线处理,从流水线出来的过程,对于我们程序员来说,是比较直观的。
I486 拥有五级流水线。分别是:取指(Fetch),译码(D1, main decode),转址(D2, translate),执行(EX, execute),写回(WB)。某个指令可以在流水线的任何一级。

但是这样的流水线有一个明显的缺陷。对于下面的指令代码,它们的功能是将两个变量的内容进行交换。
XOR a, b
XOR b, a
XOR a, b
从 8086 直到 386 处理器都没有流水线。处理器一次只能执行一条指令。再这样的架构下,上面的代码执行并不会存在问题。
但是 i486 处理器是首个拥有流水线的 x86 处理器,它执行上面的代码会发生什么呢?当你一下去观察很多指令在流水线中运行,你会觉得混乱,所以你需要回头参考上面的图。
第一步是第一条指令进入取指阶段;然后在第二步第一条指令进入译码阶段,同时第二条指令进入取指阶段;第三步第一条指令进入转址阶段,第二条指令进入译码阶段,第三条指令进入取指阶段。但是在第四步会出现问题,第一条指令会进入执行阶段,而其他指令却不能继续向前移动。第二条 xor 指令需要第一条 xor 指令计算的结果a,但是直到第一条指令执行完成才会写回。所以流水线的其他指令就会在当前流水级等待直到第一条指令的执行和写回阶段完成。第二条指令会等待第一条指令完成才能进入流水线下一级,同样第三条指令也要等待第二条指令完成。
这个现象被称为流水线阻塞或者流水线气泡。
另外一个关于流水线的问题是有些指令执行速度快,有些指令执行速度慢。这个问题在奔腾处理器的双流水线架构下显得更加明显。
奔腾 Pro 拥有 12 级流水线。当这个数字被首次宣布后,所有的程序员都倒抽了一口气,因为他们知道超标量流水线是如何工作的。如果 Intel 仍然按照以前的思路设计超标量流水线的话,流水线的阻塞和执行速度慢的指令会严重影响执行速度。但同时,Intel 宣布了完全不同的流水线设计,叫做乱序执行部件(Out-of-Order core)。单从叙述上很难理解这些改变带来的好处,但 Intel 确信这些改进是令人激动的。
让我们来更深入的看看这个乱序执行的部件吧!
乱序执行流水线
在描述乱序执行流水线时,往往是一图胜千言。所以我们主要以图例进行介绍。
CPU 流水线图例
I486 处理器拥有 5 级流水线。这种设计在现实世界中的其他处理器中很常见,而且效率不错。
而奔腾处理器的流水线比 i486 更好。两条流水线可以并行运行,而且每条流水线可以同时有多条指令在不同流水级执行。它几乎可以同时执行比 i486 多一倍的指令。
能够快速完成的指令需要等待前面执行慢的指令即使在并行流水线中也仍然是一个问题。流水线仍然是线性的,导致处理器面临性能瓶颈难以逾越。
乱序执行部件和之前处理器设计中的线性通路有很大不同,它增加了一些复杂度,引入了非线性的通路。
评论