嵌入式多节点的无线批量程序更新系统设计


一 总体设计和平台简介
项目旨在实现多ARM节点通过无线通信完成对批量节点的程序烧录,如图2.1所示。系统分为上位机、发射接收模块和待烧录节点三个部分,上位机通过ID号选择待烧录节点并通过无线模块向下广播烧录数据,各被选择节点通过无线模块接收烧录数据检查无误后存储。上位机软件设定待烧录节点的ID、烧录文件目录、发送数据包大小、发送速率等参数后将数据打包传送到基站,基站通过无线发射模块广播数据。

图2.1 多节点无线批量烧录示意
整体思想是利用已有的代码和目标代码进行比较。将两者的差异通过无线网络(802.15.4)广播出去。在每个接受节点根据收到的差异文件(也就是补丁文件patch),对原有代码进行修改(patching的过程)以达到更新程序的目的。
总体上来说本项目有两大难点,涉及到巧妙的算法设计。
1、如何用尽可能少的字节数,来表示不同代码之间的差异?
2、如何确保可靠性传输?
关于问题1,我们知道要待传输的字节数越少,对通信的要求越低。更新程序的效率也会更高。而且少的字节数也意味着丢更少的包。关于问题2,由于我们是要对代码进行修正,所以一个字节的错误可能就会造成整个程序的崩溃。这对嵌入式程序,特别是运行在成千上万个节点上的程序是不可接受的,必须保证100%的正确接受。除此两大难点(也是关键点)之外,还有一些别的附加要求。如果满足了能够提高系统的持久性。分别是:
1、使用尽可能小的RAM。因为嵌入式芯片的RAM普遍珍贵。
2、消耗尽可能少的能量。
3、更新速度尽可能的快。
项目使用的硬件平台是我们自制的智能小车eMouse 。平台采用 TI公司32位Stellaris LM3S1968微处理器,工作频率为50MHz,内含256 KB单周期Flash和64 KB单周期SRAM,flash支持可由用户管理的块保护和数据编程;板上Zigbee模块通过串口与CPU通信,模块仅提供MAC层服务,CPU与模块间以MAC帧的形式通过串口传递数据。eMouse外观如图2.2所示。

图2.2 硬件平台eMouse
项目开发系统环境为Ubuntu9.04,程序编译和下载工具分别为开源的sourcery G++和Openocd,用户界面采用java语言编写。
以下章节将对系统设计作详尽的论述。
二 程序更新设计与实现
一些传统的更新方法注重代码本身的特点。比如以函数为基本的更新单位。在每个节点上运行一个动态链接器,将新的函数重新链接到原程序。其实代码本身可以将其视为一串二进制的文本文件。代码的更新即是从一串旧的文本更新为一串新的文本。
为此我们定义了一系列基本的更新操作命令,以及两个辅助的索引指针:in_index以及out_index。in_index代表输入文件当前的索引值,而out_index代表输出文件当前的索引值。
基本的命令如下:
Copy:将in_index所指的字节复制到out_index处,并且in_index和out_index分别加1。
Replace A:将当前out_index所指的字节用A来替换,并且in_index和out_index分别加1。
Delete:in_index加1,out_index不变。实际为删除in_index所指的字节
Insert A:在当前out_index处插入A,in_index不变,out_index加1。
Kill:表示删除in_index后所有的原程序代码。
其中包含了如下的子问题:
2.1 命令的表示
通过上面所说的基本命令的组合,我们可以表示出从一个旧文件到一个新文件的过程。随之带来了一个问题。这些命令应该如何表示才能尽可能的降低补丁文件(命令的组合)的大小?
有几个需要注意的地方:
如果有连续的Copy命令,我们可以将其合并成一条命令,只要在Copy后加上表示长度的Length参数即可。
同理,如果有连续的Delete命令,也可以将其合并成一条命令,只要在Delete后加上表示长度的Length参数即可。
如果可以利用Replace命令,就不要用Delete和Insert命令的组合。这其实是另一重要的子问题:如何根据这些命令产生尽可能少补丁文件?
有五条基本命令,这样为了区别这五条命令,至少需要3个比特。
由于大多数情况下,更新的大多数是程序的参数。也就是说Copy命令的数目远远大于其他命令。我们定义这5条命令如下表所示:
表3.1
|
命令 |
操作码(最左端开始) |
操作数的长度(紧跟操作码) |
总长度(字节) |
|
Copy |
1 |
15 |
2 |
|
Delete |
000 |
13 |
2 |
|
Replace |
001XXXXX |
8 |
2 |
|
Insert |
010XXXXX |
8 |
2 |
|
Kill |
011XXXXX |
8 |
2
|
经过大量实验,我们发现连续出现Copy的情况最多,因此Copy命令操作码只有1位,即只要是最左端比特为1,则此命令为Copy命令。这样Copy的操作数为15个比特,一次能表示复制32768个字节。同理,Delete的格式同Copy时相同的,只不过其操作码较长,操作数只有13位,最多能代表删除8192个字节。实际上这也完全够用了。
Replace和Insert操作码的有效位为最左端三位,紧跟着5个比特是保留位,当前还没有用到。操作数的长度为一个字节,表示当前要替换的或者要插入的新值。
Kill命令操作码为左端3个比特,剩下的15个比特都是保留位。操作数的长度为一个字节,表示删除的起始索引。
综上可以看出,指令的格式都是定长的——2个字节。定长的代价是会浪费一定的比特。造成实际生成的补丁文件略大(由于Insert,Replace和Kill的保留位)。但正如MIPS处理器,定长的规定使得整个指令集简洁有序。虽然产生的指令条数要比X86系列的CISC机要多,但简洁的特性总是让人喜欢的。
2.2 命令的产生
这是最有挑战性的问题,如何根据前面定义的基本命令,产生尽可能小的操作指令集(补丁文件)?仔细观察发现,其实此问题包含了一个最优子结构,也就是说,我们可以用动态规划的算法来解决这个问题,保证产生的补丁文件是最小的。
假设原程序的长度为m个字节,目标程序的长度为n个字节。定义= x[1..i],Yj = y[1..j],其中x[1..i]表示源程序的第一个到第i个字节,y[1..j]表示目标程序的第一个到第j字节。用c[i,j]表示从Xi 到Yj所用的最小的代价。由于所有的命令长度均相同,故每条命令代价都为1,c[i,j]也就是代表从Xi 到Yj 所需的最小的命令数,求得最小的命令数,别且记录下其操作,我们就能得到最小的补丁文件。这样我们有以下几种情况:
-
如果最后的操作为Copy,则一定有x[i] = y[j]。原问题包含将Xi-1 转化到Yj-1的子问题。c[i,j] = c[i-1,j-1]+1
-
如果最后的操作为Replace,则一定有x[i] != y[j]。原问题包含将Xi-1 转化到Yj-1的子问题。c[i,j] = c[i-1,j-1]+1
-
如果最后的操作为 Delete,则没有什么必须满足的条件。原问题包含将Xi-1 转化到Yj的子问题。c[i,j] = c[i-1,j]+1
-
如果最后的操作为 Insert,也没有什么必须满足的条件。原问题包含将Xi 转化到Yj-1的子问题。c[i,j] = c[i,j-1]+1
-
如果最后的操作为Kill。由于Kill表示删除源程序所有剩余的字节。Kill只能出现在最后一个操作上。即完成Kill后就已经使得Xm 转化为了Yn。
c[m,n] = min(c[i,n]) + 1, 0<= i<= m
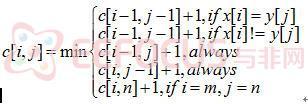
这样所有的情况都已经包含在内。对于每一个i,j我们可以求得最c[i,j]
公式从上到下依次代表了Copy,Replace,Delete,Insert和Kill这五种情况。
整体的伪代码如代码3.1所示:注意,我们不仅求得每一个c[i,j]而且记录下了与其相应的操作.op[i,j]这个数组中的每个元素为一个结构体,包含操作数以及操作码。


代码3.1得到c[i,j]以及op[i,j]
这样,我们得到了c[m,n]以及操作表。下面就是要求得操作序列。根据之前生成的操作表,采用一个递归的方法得出最小代价的操作序列。伪代码如代码3.2所示:

代码3.2生成最小代价的操作序列
这样,我们得到在定长命令下,最小的补丁文件。以上都是在PC机上进行的。即界面中的生成补丁按钮。
图3.3 界面-生成补丁功能
2.3在LM3S1968上的实现
在PC机上的部分比较容易实现(生成patch文件)。但在LM3S1968这个嵌入式芯片上进行代码的替换就不是很简单了。首先我们要确定各个文件的位置。这里为了简单起见,将flash的0x0000到0x3000处,设为更新服务程序区,初始化必要的硬件(通信、flash等),等待基站发送的命令来更新程序或者直接将控制转移给应用程序程序,本部分的程序在启动后首先运行。如果检测0x4000处为合法的应用程序,则将控制权转交给它,每个应用程序在接受到了“等待接受”命令后,又将控制权转移给更新服务程序,等待从基站发来的其他命令。需要注意的是在将控制权转移到应用程序时,中断向量表的位置,栈指针,是两个要小心设置的量。否则会造成整个系统的崩溃。而且本部分只能用汇编语言写,具体可以参见bl_start_gcc.S。0x3000到0x7000处为应用程序区,存放待运行的程序。0x7000以后存放这从主机发来的Patch文件。
整体的流程为:

图3.4更新流程图
三 可靠数据分发协议的设计与实现
3.1 Deluge协议简介
Deluge协议是一个优秀的可靠性数据分发协议,由加利福尼亚大学伯克利分校的David Culler等人在2004年提出的,首先在TinyOS1.1.8操作系统上实现。协议的设计初衷是用来进行较大规模的数据分发,比如大块数据传输和远程系统升级等。
在Deluge协议中,采用了协商式交互策略(ADV-REQ-DATA)来实现受控泛洪。而整个网络由状态机来控制数据的分发,网络中每个节点都处在MAINTAIN、RX和TX三种状态的其中一种,并且遵循该种状态下的一系列动作规则。在Deluge协议中,把将要分发的目标文件(Sobj)划分为固定大小的程序包(Spkt),由N个程序包(Spkt)组成一个程序页(Spage)。Deluge协议对整个目标文件数据的划分如图4.1所示。基于这种数据结构,Deluge协议支持空间多路技术以提高数据传输的速度,在协议中的具体实现是流水线传输(Pipelining)。

图4.1 Deluge协议中分发数据的结构
Deluge协议引入了复杂的控制信息,而目前很多无线传感器网络应用中的节点都不能支持像TinyOS这样的操作系统,因此实现起来难度较高;同时,许多数据分发的应用场景提供Deluge协议中的一些高级功能并不能明显提升网络性能,比如网络节点较少则不需要流水线数据分发,数据块较少则不需要分页机制等。基于以上原因,本设计在提出若干常见应用场景假设的基础上对Deluge协议做了简化和补充。
3.2 可靠数据分发协议的设计
在阐述具体的设计思路之前,先提出以下应用场景的假设。
假设一:网络节点不支持高级的操作系统。可以理解为必须考虑节点处理和通信能力有限,而且通信协议要从底层(如MAC层)实现。
假设二:大部分待烧录节点分布在数据基站的通讯范围之内。可以理解为通信协议不需要实现复杂的多跳通信和流水线,可以充分利用数据基站第一次数据广播,这一点下文会详细阐述。
基于以上两点假设,可靠性数据分发协议的具体设计如下。
考虑到不同平台的无线收发模块提供的服务接口和通信质量的差异以及程序更新对网络可靠性的要求,通信协议选择在网络层实现可靠数据分发的机制,协议只需要硬件平台在MAC层提供收发数据帧的应用接口即可。协议中,数据分发分为两个阶段:第一轮发送阶段和节点间交流阶段。图4.2为两个阶段通信方式示意图。
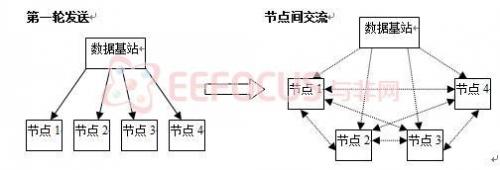
图4.2 数据分发两阶段通信方式示意图
(实线代表发送完整数据文件,虚线表示发送数据页)
1、第一轮发送阶段。
数据基站(如PC)在接收节点准备好后不间断广播数据帧,直至数据发送结束;接收节点尽力接收数据,并记录自己已有数据帧的id信息,期间不向源节点发送反馈信息。
在原始的Deluge协议中没有这一阶段,因为Deluge协议中可能无线传感器网络庞大,分布范围也较广,所以数据分发一旦启动,所有接收到数据的节点都参与到数据发送中来;而本设计中,网络充分利用了假设二中的节点分布条件,通常情况下,在第一轮发送结束后,相当大比例的节点就已经接收到了大部分的数据,而这个过程中因为只有数据基站在发送广播,网络中数据传输的效率是最高的。当然,这种节点分布条件不满足的情况也不会明显降低数据分发效率。
-
节点间交流阶段。
交流阶段参考了trickle算法的“polite gossip”策略,所有节点(包括数据基站)都参与到交流中去。每个节点的交流的目的都是相同的,即将自己拥有的数据包发送给需要的节点和请求并接收自己需要的数据包。
第2阶段是保证可靠性的关键,协议中让源节点也参与到交流中来,这是为了防止网络状况极差以至在第一轮发送结束之后所有节点接收数据的总和都不构成完整数据文件的极端情况。这一步中,节点长时间处于“维护”状态标志数据分发结束。
节点首先广播广告,每一个广告包含一个摘要(φ),摘要(φ)由两部分组成:(1)本节点的IP标识v。(2)本节点的最大可用页号p,即φ(v,p)。可用页号p的定义:页p所包含的包被节点全部接收,称页p完成。页p被完成并且它之前的所有的页(0,p)也被节点全部接收,称页p可用。节点通过广告来了解对方拥有的数据信息,继而向比自己数据更完备的节点发送数据页请求。协议中将时间分成时间片(round),在每一个时间片中,节点来决定是否广播一个广告。假设时间片的长度由Tm,i来表示,它的上下界由Tl和Th来表示,则有取Tl<Tm,i<Th。在每一个时间片i中,节点维护—个随机值ri,ri的值在Tm,i/2和Tm,i之间,ri值的范围选取是为了解决短监听问题(short—listen problem)。
交流阶段中,节点拥有“维护”、“请求”和“发送”中的人一个状态。节点在“维护”状态广播广告并听取其他节点的广播;在请求阶段向其他节点发送数据页请求,并接收对方发来的数据;在发送状态广播被请求的数据页。图4.3为状态转换示意图。主要的交流规则如下。
(1)“维护”状态规则
M1: 假设时间片i的开始时间为ti,节点在ti+ri的时间段内,若接收不到广告φ'=φ,则广播广告φ;若收到与φ不一致的广告(包括φ'=φ、广告帧和数据帧等),则调整时间片为Tl,并立即重新开始时间片;若接收到广告φ'=φ,则调整时间片为min(2*Tm,i ,Th )。
M2: 节点在收到广告φ'(v',p')中p'大于自身的最大可用页p时,转向“请求”状态,向节点v'发送数据页请求;节点收到请求帧,则转向“发送”状态,广播被请求数据页。
规则1能控制冗余广告的发送,节约网络资源,并且根据网络状况动态调整时间片长度,从而是网络资源得到有效的利用。
规则2实现从“维护”状态到“请求”和“发送”状态的转换。
(2)“请求”状态规则:
M3:若节点在向源节点发出数据页请求后节点在时间t(t为自定义时间长度,是经验值,根据网络状况而定)内没有收到数据,则再次发送请求,若累计请求次数大于k(k为自定义次数),则认为请求失败,返回“维护”状态;若节点接收到数据页,则在接收结束后返回“维护”状态。
规则3中考虑到网络的质量因素,定义了等待时间t和最大请求次数k。
(3)“发送”状态规则:
M4:节点进入“发送”状态立即广播被请求的数据页,广播结束后返回“维护”状态。
规则4中要注意的是,节点以广播的方式发送数据,这意味着处于“请求”状态的节点可以接收任何节点(不一定是它请求的指定节点)发送的符合其需要的数据包,这也是协议中避免网络冗余的一个体现。

图4.3 可靠数据分发交流阶段节点状态转换示意图
以上是本设计中可靠数据分发协议的全部内容,本文在下一节中将详细论述协议的软件设计实现。
3.3 可靠数据分发协议的软件设计实现
协议的软件设计在网络层实现,涉及到MAC层接口的调用。本节先简单介绍本设计实验平台上网络模块提供的MAC层应用接口,然后详细论述软件的设计和实现。
3.3.1 MAC层接口简介
首先做两点说明。
第一,设计中使用的MAC层接口不提供绝对可靠的网络通信。一方面是因为设计使用实验室自制的硬件平台主要用于做群体实验,而群体实验不需要可靠的网络通信,所以平台的通信模块也没有能实现可靠通信的机制;另一方面要求MAC层提供可靠通信也不是必要的。
第二,网络层只使用了MAC层提供的数据帧发送和数据帧接收两个接口,网络层的帧结构包含在MAC数据帧的数据域中。
从第一点可以看到,协议在网络层实现可靠数据传输的机制,降低了对MAC层通信质量的要求,而第二点说明协议仅仅需要MAC层提供两个最基本的应用接口。本设计中的可靠数据分发协议对底层通信的要求很低,具有较好的鲁棒性和可移植性。
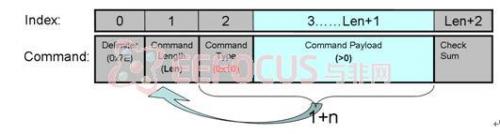
本设计实验平台上提供的MAC层数据帧发送命令结构如图4.4所示,其中区域3为数据域,包含网络层的帧结构,另外节点在MAC层以广播的方式通信,所以命令中不包含源节点和目的节点的地址信息。MAC层接收到数据帧后,将数据域分离出来存储到接收缓存区;发送数据时,将发送缓存区中的数据加上MAC层数据帧的头部和尾部并发送出去,网络层只关心发送和接收缓冲区中的数据。这里规定以下章节中提到的各种帧结构均指网络层帧结构。
图4.4 MAC层接口数据帧发送命令
3.3.2 可靠数据分发协议的数据结构设计
网络层数据要经过缓存,解析再到存储或者执行三步操作,并且不同种类的帧要区别处理,因此一个好的数据结构设计方案对简化数据处理操作和提高数据处理效率是非常有必要的。图4.5为网络层数据流图,数据帧的流向为:
从MAC层读入后放入原始数据缓冲区;
经解析后得到帧结构;
将帧结构作相关处理后仅提取页号(p)、帧号(id)和数据(data)放到写flash缓冲区;
写flash。
注意以上是数据帧的流向,除数据帧以外的其他类型帧(如请求帧,结束帧等)只执行第(1)、(2)步操作。下面着重论述图中每个阶段涉及到的数据结构。
图4.5 网络层数据流图
缓冲区Deluge_buf
Deluge_buf是一个环形缓冲区,用于缓存原始的网络层数据。缓冲区实际上是由一个环形链表、两个指针和一个整数组成。链表的每个节点用于存储实际数据,节点数目根据需要而定;一个tail指针和一个head指针,分别指链表的读出点和写入点,执行一次读出或写入操作后,tail或head指针都向前移动一次,整数的作用是统计当前链表上可用节点的数目。Deluge_buf结构体定义如下:
struct Deluge_buf {
struct data_entry queue_data[QUEUE_LENGTH]; // The data of current queue
uint8 recv_num;
uint8 queue_head;
uint8 queue_tail;
};
值得注意的是结构体data_entry中Payload项的组成在不同类型的帧中是不同的,比如数据帧中Payload包括页号p、帧号id和数据data以及数据长度data_len,而广告帧中只包含p和id,因此解析方法要根据type值来区分。
帧结构DelugeData
如图五所示,DelugeData定义了帧类型(type)等六个数据项,设计中根据不同的帧类型规定了各个数据项的含义,具体定义如表4.1所示,“—”表示该数据项在帧中没有定义。
表4.1 DelugeData中数据项含义的定义
数据项
帧类型
type
v
p
id
data
data_len
数据帧
DATA
版本号
页号
帧号
数据
数据长度
结束帧
END
版本号
页号
帧号
—
—
广告帧
ADV
版本号
页号
源节点标识
—
—
请求帧
REQ
版本号
页号
目标节点标识
—
—
命令帧
CMD
命令参数
—
—
—
—
3、缓冲区Flash_buf
因为写flash操作比网络传输慢得多,为了避免写flash拖慢整个数据分发速度,建立缓冲区Flash_buf用于缓存准备好的数据。Flash_buf也是一个环形缓冲区,原理和Deluge_buf相同。缓冲区的节点包含p、id、data三个数据项和指针域next,其中data是要写入flash的数据,p和id用于计算待写入的flash地址。
3.3.3 可靠数据分发协议的软件架构设计
可靠数据分发协议的软件构架设计包括发送端和接收端两块内容。发送端软件运行在数据基站上,分为两个阶段,第一阶段通知节点连续地发送整个文件,第二阶段运行状态机参与到节点的交流中去;接收端软件运行在待烧录节点上,第一个阶段尽可能多的接收基站发送来的数据,第二阶参与节点间讨论。因为发送端第一阶段软件比较简单,第二阶段和接收端相同,所以这里只重点介绍接收端的软件构架设计。
第一阶段:
程序完成初始化后进入准备接收状态,当数据帧到来时将数据提取出来写到flash相应的地址(地址由页号p和帧号id计算得到),并将该帧标记为“完成帧”;若接收到结束帧,则记录结束帧的页号pmax和帧号idmax并进入第二阶段;若接收到其他类型帧则直接进入第二阶段。第一阶段的软件流程图如图4.6所示。

评论