
仿真電子舌系統的设计与实现,软硬件协同

- 研究背景
電子舌系統,在意義上藉由特殊的化學感測器上的感測薄膜,類似於人體的舌頭能夠感覺到酸、甜、苦、辣、及美味。而在連結到電子舌感測器需要前端讀出電路、再藉由數位類比轉換器以及後端的數位訊號處理器來分辨是哪種溶液。這就像是我們的舌頭送出味覺給我們的大腦做處理。因此在應用上電子舌系統係已取代人類味覺,可以在短時間內分辨液相溶液中特定成分及其含量,可進行多項物種的檢測或生理參數之監測,多數的電子舌系統都以電化學式生物感測器為前端元件研發而成,因此要如何有效地利用感測結果,有效地經由演算法辨別來辨識其存在於溶液的物種,是一個相當具有研究的議題。
- 研究動機與目的
近年來,智慧型陣列感測器已受到各領域的注目關切。不同於傳統感測器設計,目標在於要能夠設計單一且高感測度智慧型感測器陣列並且結合後端處理來達到類似於人體的感官系統。
離子敏感型場效電晶體(Ion-Sensitive Field-Effect Transistor, ISFET)係經常用於電子舌系統下的電化學感測器。ISFET可用來感測在具單一離子的化學溶液,來加以分析其單一離子的活性濃度。但通常在化學溶液中,通常具有兩種或是以上更多種離子,像飲用水中最常可以在寶特瓶上所列出的有鈉、鉀、鈣…。因離子敏感型場效電晶體經由讀出電路讀出量測的訊號與濃度線性相關,因此可利用此結果應用在線性回歸理論,像是任何的監督式學習理論。然而,監督式學習通常需要許多的校正點,而ISFET不僅僅對單離子具感測度,對於在一混合離子濃度溶液中,許多的干擾離子也會使得ISFET讀出的響應為非線性函數。除此之外,還有一些暫時的不穩定ISFET特性會照成在使用上額外的校正程序,因此必須先了解ISFET的動態行為。
在ISFET的狀況下,智慧型陣列式方法可處理允許高精準多重成分分析,因ISFET反應是由單一特定離子活性及其他離子(如干擾離子),因此在盲源分離(Blind Source Separation)的過程中,可以藉由實際的實驗來得到與主要離子及其他離子的行為模型,來應用在盲源分離技術下,又稱為ISFETSS (ISFET Source Separation)。盲源分離理論是一個利用陣列式處理方式將混合訊號作分離,並且找到其原始訊號之新穎無監督式學習理論,因此此研究目的是要將ISFET利用讀出電路讀取到之訊號經由如此處理的方式找到其反應之來源訊號,並且將其想法硬體化實現。
- 研究方法及流程
本設計使用Spartan 3A DSP 1800A進行FPGA驗證,由於在硬體設計方面,必須撰寫VHDL/Verilog、熟悉Xilinx的工具、FPGA內部的架構,為了減少設計的時間,本文採用System Generator建置整個系統的架構,並且使用Matlab軟體驗算其結果是否正確,驗證完成後,即可採用Hardware Co-simulation中Ethernet Point-to-Point的方法,將資料透過網路線與PC和FPGA進行資料的傳輸及驗證。
- ISFET簡介
ISFET的運作係將感測膜浸入待測溶液中,由於感測膜與半導體表面僅隔一層極薄的介電層,因此感測膜與溶液間的介面勢將影響半導體表面,使表面反轉層中的載子電荷密度發生變化,進而改變ISFET元件的通道電流。感測膜與溶液間的介面勢又與溶液中的離子濃度有關,故可利用ISFET在不同氫離子濃度的溶液形成不同之介面勢,造成通道電流的不同以檢測溶液中的氫離子濃度,此即為氫離子感測場效電晶體的基本工作原理。
ISFET元件的感測膜與待測溶液接觸時,將在待測溶液/絕緣層介面處形成電雙層,而有介面勢,介面勢大小與感測膜材料的特性及待測溶液中氫離子濃度有關。而為降低外界干擾因素並且提高量測的電位,故在ISFET量測時加入參考電極以穩定電位,所以其間會增加一參考電極與溶液間的電位勢和感測膜與溶液間的介面勢。
- ISFET之不理想效應
ISFET在實際的應用上存在著許多非理想效應,例如光源、雜訊、遲滯、時漂、溫度、基底、流速效應以及生命週期等非理想效應。上述之非理想效應均會影響酸鹼度計對pH值量測的準確性及效能,因此在實驗過程中必須要考量以上之效應,來使得實驗結果符合預期。
- 離子選擇係數
離子選擇係數是離子選擇電極之重要參數,因一般離子感測器於溶液中電位反應並不易做到僅針對一特定離子而不受其他相同帶電性離子影響,故要判斷其他離子之干擾是否造成其誤差還在範圍之內,固使用選擇係數K(Selectivity coefficient)作為指標,依據國際單位純應用化學協會(International Union of Pure and Applied Chemistry, IUPAC)在1994年所發表之電壓式電化學感測器準則[6],電壓式電化學感測器於離子干擾實驗中,Nikolsky-Eisenman 提出一適合之方程式。主要因電極干擾參數不變,且於已知干擾離子濃度之溶液中求得受測離子濃度實際值。公式敘述如下:
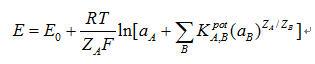
其中E0為常數、ZA為離子電荷、ZB為干擾離子電荷、aA為主要受測離子活性、aB為干擾離子活性、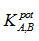 為主要受測離子(A)對干擾離子(B)之選擇係數。
為主要受測離子(A)對干擾離子(B)之選擇係數。
值越大代表主要離子抗干擾之程度越佳,代表在一具高濃度之干擾離子溶液下還可測得其主要離子之濃度。而在之量測方法分為兩大類:混合溶液法(Mixed Solution Methods, MSM)以及分離溶液法(Separate Solution Methods, SSM);而最廣泛地使用是混合溶液法中的干擾離子固定法(Fixed Interference Method, FIM),這種方法最早發表於1975年的IUPAC協會。而在之後又發展了許多近似的理論,而本文在實驗中主要使用為干擾離子固定法(Fixed Interference Method, FIM)、主要離子固定法(Fixed Primary ion Method, FPM)兩種方法。
- 干擾離子固定法
干擾離子固定法(Fixed Interference Method, FIM)此實驗方法為固定背景溶液當中之干擾離子濃度,並添加與干擾離子相同帶電性之主要離子,使溶液當中之主要離子濃度改變,但干擾離子之濃度並不改變。其選擇係數K值之計算方式如下:
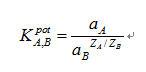
為主離子對干擾離子之選擇係數、ZA為主離子之價數、ZB為干擾離子之價數。選擇係數是指可測得的極限的主離子濃度大小。
-
獨立成份分析簡介
獨立成份分析(Independent Component Analysis, ICA)是近幾年發展出來的新方法所希望得到的表徵被稱為成份,顧名思義,目的是要讓成份之間的統計相依性(Statistical dependence)降到最小,也就是使成份彼此之間互為獨立。因此獨立成份分析就是要找到統計上獨立及非高斯的成份。在目前應用領域上有影像處理、聲音訊號處理、電信及金融分析上。
獨立成份分析起初是在一個雞尾酒派對上開始被探討的,一個雞尾酒派對上有著樂團的表演聲(S1)以及人們的喧鬧聲(S2),而放在不同位置的兩個麥克風(x1, x2)是以怎樣的比例去收音得到的,假設不考慮任何回音及噪音影響,以下列方程式表示:
X1(t) = a11×S1(t)+a12×S2(t)
X2(t) = a21×S1(t)+a22×S2(t)
因此利用矩陣的方式可以得到一個矩陣A,相關的表示式為àX=AS、S=(S1,S2…Sn)T為潛在的變數(獨立的成份),A是一個混合矩陣(Mixing matrix)。就廣義的定義來說ICA就是要找到一個線性轉換如式子:àu=WX。u為獨立成份S的估計值,W則是一個去相關矩陣(Unmixing matrix),目的是要使得各成份間u=(u1, u2, u3…un)T盡可能的互相獨立,也就是若將某種量測獨立的函數F(u1, u2, u3…un)最大化時,此時W=A-1,因此ICA估測出來的u=(u1, u2, u3…un)T就等於原來的潛在變數S=(S1,S2…Sn)T。可以下圖來表示:
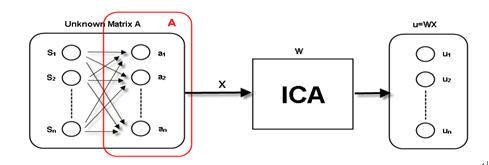
圖2-3 盲源分離架構示意圖
但為了有效的簡化問題,通常會先進行前置的演算法處理,良好的前置處理能夠使得盲源分離的問題變的較容易解決,亦能有助於之後將相關的訊號轉變成非相關的訊號。以下就先以ICA的前置處理來做討論:
-
預處理動作
資料置中(Centering):
假使獨立訊號源和我們所收集到混合訊號的平均值不為零,那麼在演算法的推導過程會變的比較複雜,會增加許多的運算量,所以在這種情況下我們可以將所收集到的訊號減去它們的平均值,使其平均值為零、如下所示:
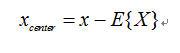
此外,經過資料置中處理後的混合訊號X,矩陣A依然不會改變;雖然只有對接收到的訊號作資料置中的運算,但事實上也對訊號源做了資料置中的運算:
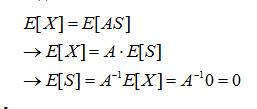
白化(Whitening):
在作獨立成分分析前如果能透過前置運算處理的方式將取得的訊號轉變為非相關,那麼則可以讓運算的訊號能夠更為接近相互獨立;至於白化則是介於非相關與相互獨立之間的另一種關係,除了訊號為非相關,而且變異數的值為”1”,假使Z為white (平均值為0的隨機向量),那麼它的變異矩陣的數值為單位矩陣。
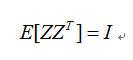
資料白化的目的主要是去找到一個白化矩陣V用來將混合訊號做轉換:
Z=V×X
而一般常使用的方法就主要成分分析即是對混合訊號變異矩陣作特徵值分解(Eigenvalue Decomposition)

上式的矩陣E是Eigenvector所組成的正交矩陣;而矩陣D則是其相對應的特徵值所形成的對角線矩陣,矩陣V可改寫為
V = ED-1/2ET
其中
如上式所示代入變異矩陣判斷是否為單位矩陣,並檢查經由白化矩陣運算後的矩陣Z是否已變為白化。
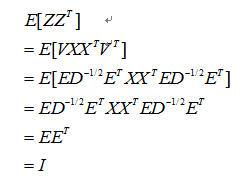
資料白化的運算,可當作是將混合矩陣A作線性轉換,因此可改寫為
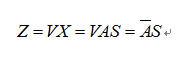
其中A可視為經過轉換後的混合矩陣;此外當訊號經過白化後,其變異矩陣以上式代換後可得:
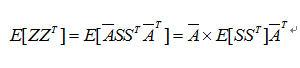
又E{Si2}=I
因此又可以知道訊號源的平均值等於”0”,而且變異數等於”1”;此外訊號源之間又相互獨立關係,所以E[SST] = I 那麼
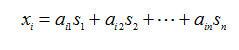
由以上推導可知經過白化運算後的混合矩陣為一個正交矩陣,這代表只要找到相互正交的向量,及可以找到其簡化矩陣,方便簡化整個演算法。
-
獨立成份分析之假設與限制
對獨立成份分析(ICA)研究的最初因素是先前所提到的雞尾酒派對的問題,作為真實混合過程是非常粗略的近似的假設,ICA模型是可以接受的,也是盲處理的起點。實際上,在不同情況下的信號分離問題上,ICA有著不同的形式。以雞尾酒派對中信號分離為例,由於聲波傳播速度較慢,到達各麥克風的時間不同,而在室內其實也會存在著回波,所建立的模型又不大一樣,而室內隨著走來走去的人們,也會照成其聲波的不一樣以及變化。但在考慮其它效應之前,必須還是得先討論基本的ICA模型。
基本的ICA模型是一個生成模型(generative model),它描述所觀測的數據是如何由一個混合過程所產生。假設有n個統計上相互獨立的隨機向量s1,s2,…sn,其線性組合生成n個隨機變量x1,x2,…,xn
i=1,2,…,n
式中aij, i, j=1,2,…,n是實數。為了方便起見,使用向量-矩陣記號來表示。令x=[x1,x2,…,xn]T,s=[s1,s2,…sn]T和A是元素為aij的矩陣。對瞬時混合模型,為了簡化寫法混合模型可寫成:
X=AS
為了保證ICA模型是可解的,必須作出一些假定和限制。
第一項假設是統計上的獨立性。對於可估計的模型來講,這項假設是為最為重要的,也是ICA方法可用於許多不同應用領域的主要原因。而在統計上的獨立性定義是以機率密度來定義,即聯合機率密度應可分解為邊緣密度的乘積

第二項假設是非高斯分佈。如果所觀測變量具有高斯分佈,其高階累積量為零,因此就無法根據高階信息估計ICA模型。或者說,由於混合矩陣A是正交的,A-1=AT,它不改變機率密度函數,原來的分佈和混合的分佈相同,無法從混合信號推得混合矩陣。從圖形上來看,高斯變量的密度是旋轉對稱的,不包含A的列方向上的任何信息,因此無法估計A。
第三項假設了未知混合矩陣中獨立成份數等於觀測混合訊號數,以簡化估計。需要說明的是,當獨立成份數小於觀測混合訊號數時,可利用主成份分析(PCA)降低數據的維度,使得與觀測訊號相同。
在滿足以上三項假設的情況下,通過計算矩陣A的逆矩陣W,就可以解出獨立成份
s = Wx
- 主成分分析系統架構圖
下圖為整個主成分分析系統之區塊圖(Fig.1)。
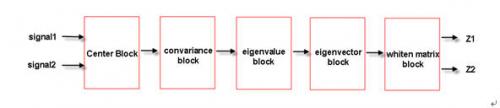
Fig. 1主成分分析系統之區塊圖
下圖區塊為系統中,其中一個置中功能區塊(Fig.2)及內部詳細圖(Fig.3)。
Fig. 2置中區塊
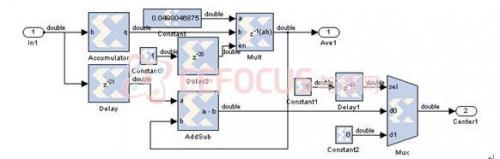
Fig. 3置中區塊內部架構圖

Fig. 4置中區塊燒錄驗證架構
Fig. 5置中區塊燒錄結果
在進行白化步驟之前,必須要先將兩輸入訊號之共變異數求出。因此必須要再次的得到置中後之訊號平均值進行相乘及累加之動作。由下式說明:
變異數定義:
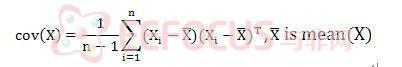
因此必須要將得到兩兩訊號之訊號平均值,再次的置中後,再兩兩相乘得到四組變異數(covariance)之結果。
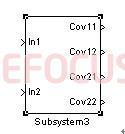
Fig. 6變異數區塊

Fig. 7變異數內部架構圖
Fig. 8變異數區塊燒錄驗證架構
|
covariance from matlab |
covariance from system generator |
|
|
cov11 |
0.9895 |
0.983 |
|
cov12 |
-0.3158 |
-0.3217 |
|
cov21 |
-0.3158 |
-0.3217 |
|
cov22 |
2.8289 |
2.832 |
在特徵值的部分,已將特徵值D有效地求出
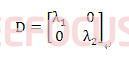
再經由特徵值有效地求出特徵向量Q之值,因特徵向量非唯一解,而Matlab求唯一解的方法為利用正交矩陣QQT=I的概念去求出特徵向量之唯一解。但在實際計算上僅需計算相對比例解即可計算出特徵向量,並不會影響實際應用之解。
Fig. 9 特徵值區塊圖
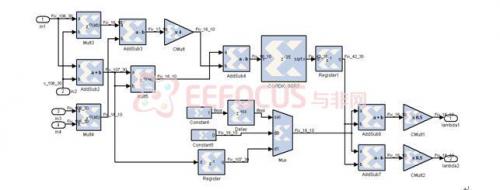
Fig. 10特徵值內部架構圖
因此再藉由特徵向量Q有效地求出白化矩陣V
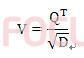
因此將白化矩陣V乘上原始訊號X後,可得到取特徵值後之訊號Z,為了要證明經白化矩陣之訊號為白化後之矩陣,因此必須要證明Z*ZT=I
下圖為目前所建構之白化系統System generator 之全圖。
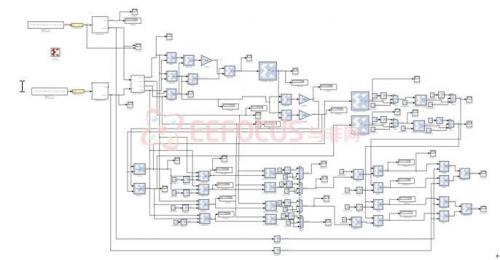
Fig. 11白化系統System generator 之全圖
接著以散佈圖概念去說明:
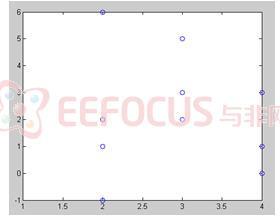
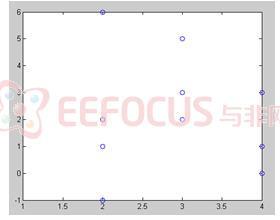
左圖為原始訊號之結果,相較於右圖較為分散也就是說原始兩個訊號相關性較低,也無明顯之特徵去表示此訊號。而右圖為左圖取白化後得到之訊號,具較大的相關性。
由於系統架構過於龐大,FPGA無法一次將完整的系統進行硬體部分的驗證,因此將此系統分區塊驗證並且得到與原本相同之結果。
评论