基于定点DSP处理芯片的语音信号识别


近年来,高性能数字信号处理芯片DSP(Digital Signal Process)技术的迅速发展,为语音识别的实时实现提供了可能,其中,AD公司的数字信号处理芯片以其良好的性价比和代码的可移植性被广泛地应用于各个领域。因此,我们采用AD公司的定点DSP处理芯片ADSP2181实现了语音信号的识别。
1 语音识别的基本过程
根据实际中的应用不同,语音识别系统可以分为:特定人与非特定人的识别、独立词与连续词的识别、小词汇量与大词汇量以及无限词汇量的识别。但无论那种语音识别系统,其基本原理和处理方法都大体类似。一个典型的语音识别系统的原理图如图1所示。
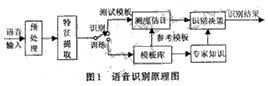
语音识别过程主要包括语音信号的预处理、特征提取、模式匹配几个部分。预处理包括预滤波、采样和量化、加窗、端点检测、预加重等过程。语音信号识别最重要的一环就是特征参数提取。提取的特征参数必须满足以下的要求:
(1)提取的特征参数能有效地代表语音特征,具有很好的区分性;
(2)各阶参数之间有良好的独立性;
(3)特征参数要计算方便,最好有高效的算法,以保证语音识别的实时实现。
在训练阶段,将特征参数进行一定的处理后,为每个词条建立一个模型,保存为模板库。在识别阶段,语音信号经过相同的通道得到语音特征参数,生成测试模板,与参考模板进行匹配,将匹配分数最高的参考模板作为识别结果。同时,还可以在很多先验知识的帮助下,提高识别的准确率。
2 系统的硬件结构
2.1 ADSP2181的特点
AD公司的DSP处理芯片ADSP2181是一种16b的定点DSP芯片,他内部存储空间大、运算功能强、接口能力强。有以下的主要特点:
(1)采用哈佛结构,外接16.67MHz晶振,指令周期为30ns,指令速度为33MI/s,所有指令单周期执行;
(2)片内集成了80 kB的存储器:16 kB字的(24b)的程序存储器和16kB字(16b)的数据存储器;
(3)内部有3个独立的计算单元:算术逻辑单元(ALU)、乘累加器(MAC)和桶形移位器(SHIFT),其中乘累加器支持多精度和自动无偏差舍人;
(4)一个16b的内部DMA端口(1DMA),供片内存储器的高速存取;一个8b自举DMA(BDMA)口,用于从自举程序存储器中装载数据和程序;
(5)6个外部中断,并且可以设置优先级或屏蔽等。
由于ADSP2181以上的特点,使得该芯片构成的系统体积小、性能高、成本和功耗低,能较好地实现语音识别算法
2.2 系统的硬件结构
在构成语音识别电路时,我们采用了ADSP2181的主从结构设计方式,通过IDMA口由CPU装载程序。语音识别系统的硬件结构如图2所示。
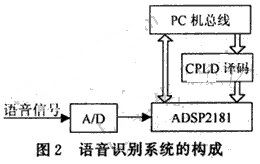
在这种结构中,PC机为主CPU,ADSP2181为从CPU,由PC机通过IDMA口将程序装载到ADSP2181的内部存储器中。PC机总线通过CPLD译码,形成IRD,IWR,IAL,IS等控制信号,与ADSP2181的IDMA口相连。这样,在ADSP2181全速运行时,主机可以查询从机的运行状态,可以访问到ADSP2181内部所有的程序存储器和数据存储器。这对程序的编译和调试,以及语音信号的实时处理带来了极大的方便。
3 语音识别的DSP实现技术
3.1 浮点运算的定点实现
在语音识别的算法中,有许多的浮点运算。用定点DSP来实现浮点运算是在编写语音识别程序中需要首先解决的问题。这个问题可以通过数的定标方法来实现。数的定标就是决定小数点在定点数中的位置。Q表示法是一种常用的定标方法。其表示机制是:
设定点数是J,浮点数是)/,则Q法表示的定点数与浮点数的转换关系为:
浮点数)/转换为定点数x:x= (int)y×2Q;
定点数z转换为浮点数y:y =(float)x×2-Q。
3.2 数据精度的处理
用16b的定点DSP实现语音识别算法时,虽然程序的运行速度提高了,但是数据精度比较低。这可能由于中间过程的累计误差而引起运算结果的不正确。为了提高数据的运算精度,在程序中采用了以下的处理方法:
(1)扩展精度
在精度要求比较高的地方,将计算的中间变量采用32b,甚至48b来表示。这样,在指令条数增加不多的情况下却使运算精度大大提高了。
(2)采用伪浮点法来表示浮点数
伪浮点法即用尾数+指数的方法来表示浮点数。这时,数据块的尾数可以采用Q1.15数据格式,数据块的指数相同。这种表示数据的方法有足够大的数据范围,可以完全满足数据精度的要求,但是需要自己编写一套指数和尾数运算库,会额外增加程序的指令数和运算量,不利于实时实现。
以上两种方法,都可以提高运算精度,但在实际操作时,要根据系统的要求和算法的复杂度,来权衡考虑。
3.3 变量的维护
在高级语言中,有全局变量与局部变量存储的区别,但在DSP程序中,所有声明的变量在链接时都会分给数据空间。所以如果按照高级语言那样定义局部变量,就会浪费大量的DSP存储空间,这对数据空间较为紧张的定点DSP来说,显然是不合理的。为了节省存储空间,在编写DSP程序时,最好维护好一张变量表。每进入一个DSP子模块时,不要急于分配新的局部变量,应优先使用已分配但不用的变量。只有在不够时才分配新的局部变量。
3.4 循环嵌套的处理
语音识别算法的实现,有许多是在循环中实现的。对于循环的处理,需要注意以下几个问题:
(1)ADSP2100系列DSP芯片中,循环嵌套最多不能超过4重,否则就会发生堆栈溢出,导致程序不能正确执行。但在语音识别的DSP程序中,包括中断在内的嵌套程序往往超过4重。这时不能使用DSP提供的do…unTIl…指令,只能自己设计出一些循环变量,自己维护这些变量。由于这时没有使用DSP的循环堆栈,所以也不会导致堆栈溢出。另外,如果采用jump指令从循环指令中跳出,则必须维护好PC,LOOP和CNTR三个堆栈的指针。
(2)尽量减少循环体内的指令数。在多重循环的内部,减少指令数有利于降低程序的执行次数。这样有利于减少程序的执行时间、提高操作的实时性。
3.5 采用模块化的程序设计方法
在语音识别算法的实现中,为了便于程序的设计和调试,采用了模块化的程序设计方法。以语音识别的基本过程为依据进行模块划分,每个模块再划分为若干个子模块,然后以模块为单元进行编程和调试。在编写程序之前,首先用高级语言对每个模块进行算法仿真,在此基础上再进行汇编程序的编写。在调试时,可以采用高级语言与汇编语言对比的调试方式,这样可以通过跟踪高级语言与汇编语言的中间状态,来验证汇编语言的正确性,并及时的发现和修改错误,缩短编程周期。另外,在程序的编写过程中,应在关键的部分加上必要的注释与说明,以增强程序的可读性。
在总调时,需要在各模块中设置好相应的人口参数与出口参数,维护好堆栈指针与中间变量等。
3.6 利用C语言与汇编语言的混合编程
现在,大多数的DSP芯片都支持汇编语言与C或C++语言的混合编程,ADSP2181也不例外。用C语言开发DSP程序具有缩短开发周期、降低程序复杂度的优点,但是,程序的执行效率却不高,会增加额外的机器周期,不利于程序的实时实现。为此,在用C语言编写语音识别算法时,我们采用了定点化处理技术。ADSP2181是16位定点处理器,定点化处理应注意以下几个问题:
(1)ADSP2181支持小数和整数两种运算方式,在计算时应选择小数方式,使计算结果的绝对值都小于1;
(2)用双字定点运算库代替C语言的浮点库,提高运算精度;
(3)注意在每次乘加运算之后进行饱和操作,防止结果的上溢和下溢;
(4)循环处理后的一组数据可能有不同的指数,要进行归一化处理,以便后续定点操作对指数和尾数部分分别处理。
4 结 语
用定点DSP芯片构成的语音识别系统有着广泛的应用前景,在编写语音识别算法时,对其进行定点化处理以及一些原则和方法对其他类似的算法也有着现实指导意义。在实际应用中,应注意根据DSP芯片的特点,对算法进行优化,使得DSP芯片的性能得到充分的发挥。
评论