
基于SRAM的核心路由器交换矩阵输入端口设计

0引言
随着光纤通信技术的飞速发展,路由器的数据处理速度成为网络通信的主要瓶颈,交换矩阵作为核心路由器的重要组成部分则严重制约了路由器的传输速率。
目前核心路由器交换结构使用较多的有共享内存和Crossbar两种。共享内存结构通过共享输入和输出端口存储器件,减少了对总体存储空间的需求。共享内存结构相对简单,交换效率可根据需求不断优化。共享内存交换结构的交换性能取决于共享内存的存取速率,可扩展性较差,尤其当板卡端口数量较多时,交换效率有所下降。
Crossbar是一种严格的非阻塞交换结构,输入/输出之间可建立多条通路。Crossbar采用连接式,即N×N的交叉矩阵。Crossbar使用调度器,根据各输入点相关的信息,运算调度算法得到输入和输出之间的一个匹配,并配置相应交叉点。调度器的效率非常关键,决定了Crossbar的交换速率[1-3],因此调度算法必须高度完善。但Crossbar同样存在扩展性的问题,即交换矩阵的交叉点会随着输入/输出数量的增多呈指数增长。为维持无阻塞交换,需不断完善和改进调度算法,代价是开发的技术成本越来越高,核心交换芯片的面积也越来越大。另外,Crossbar也同样不能避免排队仲裁,传输效率受到一定影响和限制。但相比共享内存结构,Crossbar效率和扩展性都比较好[4],目前大部分高端路由器都使用Crossbar交换结构。
基于静态随机存储器(SRAM)的交换矩阵输入端口虚拟输出队列(VOQ)的设计同时结合了共享内存和Crossbar两种交换方式的优点,将输入端口中的数据缓冲区移至片外,用高效地调度算法对虚拟输出队列进行调度,可以有效的减小核心交换芯片的面积,并提高数据报文的读取速率。
1系统总体设计
由于核心路由器交换矩阵硬件实现简单,已经在越来越多的ATM交换机和高性能路由器中使用。当输入端口使用单一的FIFO排队机制时,HOL(Headof Line)阻塞使得开关吞吐率最多只能利用58%[5],因此,在目前输入缓冲的交换设备中,输入端口一般采用VOQ虚拟输出队列技术,即每个输入端口为到达不同输出端口的信元设置不同的FIFO队列。虚拟输出队列技术的采用消除了HOL阻塞。
核心路由器交换矩阵主要由三个模块组成,即调度模块,输入模块,输出模块。调度模块主要用来分析输入端口的缓存数据报文的目的地址,根据输入端口各个虚拟输出队列的调度请求,使用iSLIP调度算法8控制输入端口与输出端口之间的连接,防止队列的链头阻塞[6]。
输入模块主要是用来将从线卡上接收的数据报文存入不同的基于SRAM的虚拟输出队列,同时向调度器发出调度请求,当接收到调度指令后,将报文发往输出端口。输出模块是用来接收输入端口发来的数据报文,并将其重新组合成完整的数据包发送出去,同时给调度器一个反馈指令,交换矩阵的系统框图如图1所示。

图1交换矩阵整体结构
2VOQ虚拟输出队列设计
影响Crossbar交换效率的因素主要是输入排除链头阻塞问题和调度算法的选择。输入排队链头阻塞问题的解决方案就是采用给每个输入到输出建立一个虚拟缓冲队列的输入排队交换内核的体系结构,基本思想是每一个输入端口在其输入缓冲器中为每一个输出端口保存一个先进先出(FIFO)队列。对于8×8的交换结构,共有8×8个VOQ.到达输入端口的信元按照它的输出端口,置入相应的VOQ队列中。在每个交换时隙,调度器调度所有VOQ,使得每一个输出端口只有一个VOQ接受服务,然后发送其最前端的分组,不仅消除了由FIFO队列造成的链头阻塞,更不用考虑设置加速比问题,VOQ的具体结构如图2所示。

图2VOQ虚拟输出队列设计
VOQ方式将目的输出端口不同的信元放在不同的队列中缓存,因此发往不同输出端口的信元相互不存在HOL阻塞。在某些调度算法下,VOQ方式可100%获得交换开关的利用率。目前CiscoGSR12000,BBNMGR等路由器都采用VOQ方式组织输入队列。消除HOL阻塞后,交换开关仍存在另外两种阻塞,即输入端口阻塞和输出端口阻塞。由同一输入端口不同VOQ队列中的信元竞争输入端口而产生的阻塞称为输入端口阻塞,由不同输入端口的信元竞争同一输出端口而产生的阻塞称为输出端口阻塞。调度器根据各输入端口VOQ队列的状态决定Crossbar内部的拓扑关系,从而解决上述两种阻塞[7]。系统主要由交换阵列、调度器、输入控制器、输出控制器和SRAM组成。输入控制器从线卡接收信元,根据其目的端口号将其存入双端口SRAM中,每个输入端口共8个队列,分别存放发往不同输出端口的信元。输入端口控制器根据队列的空满情况向调度器发出请求[8]。调度器根据各输入端口的请求公平地分配输出端口,并将调度结果传送到Crossbar交换阵列和各输入/输出控制器。输入端口控制器接收到调度结果后,从相应的VOQ队列取出一个信元送交换阵列交换。同时输出端口控制器根据调度结果,将接收的信元放入相应的输出端口寄存器中。若输出接口控制器检测到寄存器中有重组完毕的报文,将报文发往相应的线卡中。
3输入端口设计
调度算法的选择和输入排队链头阻塞问题是影响交换矩阵交换速率的关键因素。i-SLIP调度算法的硬件实现比较简单,并且支持优先级调度,可以很好地满足调度的要求。输入端口VOQ队列的设计则可以很好的解决链头阻塞问题,由于输入端口在交换芯片中占据了很大的面积,所以将报文缓冲区移到片外可以显著地降低交换芯片的面积,输入端口的设计如图3所示。
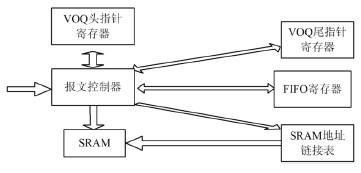
图3输入端口控制器设计
从线卡传输到交换网络输入端口的数据包有着固定的长度,它的长度共有72位,包括6位的包头和66位的包数据,其中包头的前3位是源地址,后3位是目的地址[9]。当报文控制器接收到从线卡传输来的72位的数据包时,便将其存入SRAM中的空地址中,FIFO寄存器是专门用来存放SRAM中的空地址,报文控制器根据FIFO寄存器的空地址将数据包存入到SRAM中,同时更新SRAM地址链接表和VOQ尾指针寄存器,以便接收下一个数据包。当需要从SRAM中读取数据包时,首先根据VOQ头指针寄存器找到SRAM地址链接表,SRAM地址链接表中存放的是数据包在SRAM中的地址,然后根据SRAM地址链接表找到需要从SRAM中读取的数据包的地址,从而读取所需要的数据,同时更新VOQ头指针寄存器和SRAM地址链接表[10]。
由于报文的头尾标志用2b定义,因此具有很好的故障恢复能力。例如因此硬件传输时受到外界干扰,10标志变成n,这时不需任何例外处理,带来的危害仅仅影响连续的两个报文(两个报文合并成一个)。
4SRAM读写测试
交换矩阵输入端口的设计取决于能否根据输入端口中FIFO寄存器中的空的SRAM的地址和SRAM地址链接表准确地读取SRAM中的数据报文。该输入端口设计以AteraDE-115开发板上的SRAM芯片为基础,编写SRAM的仿真模型,该芯片的存储容量为2MB,并在Modelsim中完成了对设计的验证。仿真结果如图4所示。

图4SRAM仿真模型测试
5结语
本文设计了一个基于SRAM的交换矩阵的输入端口,该设计有效的消除了输入排队链头阻塞的问题,极大地提高交换开关的利用率,将输入端口数据报文存放在片外SRAM中,可以显著降低交换芯片的面积,提高虚拟队列中数据报文的读取速度,并在Altera开发板上完成了验证,系统性能稳定,具有很好的应用前景与研究意义。
评论